At the risk of sounding harsh, I cannot remember the last time I interviewed a QA engineer who could clearly explain to me what a Performance Test is. Even more worrisome, when they described how they usually run performance test, they could only describe the mechanics of the test (“I ran JMeter”). More often than not, the tests were wrong, and, in any case, they could not interpret the results (largely because they did not know what numbers to look at).
So here is a basic description of what a performance test is and the important steps to follow – as well as one of the most common mistakes.
Note for illustration purposes, I’ll use the term site (e.g. retail e-commerce site), but this post applies identically to SaaS services.
Typical Performance Test
The primary performance test that engineers want to run on a product is: “How many users will our product support?”. This typically translates to “How many concurrent users can the current code and infrastructure support with acceptable response time?”
Another performance question is to determine how many total users can be supported. This problem is rarer, and we won’t cover it here.
The first challenge is: “what is a concurrent user?” While the answer is intuitively obvious: “the number of people using the site at the same time”, we still need to define what “at the same time” means. In particular, it does NOT mean “exactly” at the same time, i.e. within the same micro-second.
This incorrect “within the same microsecond” interpretation actually leads to the most common error in performance testing, where testers set up N JMeter clients (where N is the target number of concurrent users), launch them at the same time, and measure the time it takes until the last clients receives a response. This test does not measure concurrent users – in real life, users arrive randomly on a site, not at the exact same time. This is illustrated in the two figures below. Both represent 1,000 users using the site during a period of one hour. The “Burst” figure illustrates the “bad” test when all 1,000 users hit the same in the first minute (and then no activity in the remaining 59 minutes). While the correct scenario is likely to be closer to the second picture, where during each of the 60 minutes an average of 16.66 users hit the site (1,000 users / 60 minutes). However, in any given minute the number of users can vary between 5 and 25 (for example).
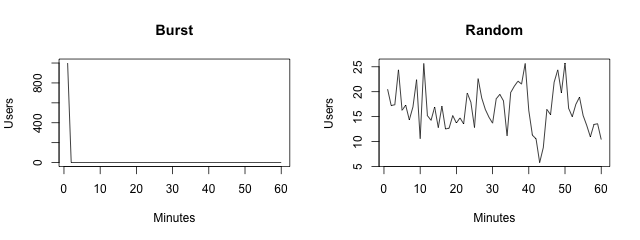
Another way of expressing that a site has 1,000 visitors per hour, is that a new visitor hits the site every 3.6 sec (3,600 seconds per hour / 1,000). Consequently, we can program JMeter to hit the site following a pseudo-random sequence of mean 3.6 sec and standard deviation 1 second (e.g.).
Depending on the length of our standard visitor visit, we will need to deploy multiple clients. For example, if each visit simulation takes a minute, we will need an average of 16.6 clients (60 sec per minute / 3.6 sec) to perform the simulation
How Many Concurrent Users to Use?
The excellent article: How do you find the peak concurrent users on your site? describes in details how we can find the peak number of visits during a given hour on the site (for performance testing, we care about visits – rather than visitors)
Of course, the key is to know our site well enough to identify the actual day(s) and hour(s) when we have the peak traffic.
However, we cannot stop there. The purpose of the test is to give us confidence that our site will be able to handle the load in the future. So the historic peak number of visits needs to be interpolated for the anticipated lifetime of the release we are certifying. E.g. if we want to be ready for the upcoming Black Monday, we need to take last year’s numbers and increase them based on the projected traffic from Sales & Marketing … plus an extra 25% as a safety buffer.
What is a Visit? What User Actions to Execute?
Now that we have figured out, how many visits we need to run, and how often, we need to figure out “what’s a visit”? There are 2 principal ways to answer the question:
- a visit is a isolated user action
- a visit is the simulation of an actual visit of a typical user.
Testing the Performance of a Isolated User Action
While we assume, and hope, that the visitors on our site don’t limit themselves to a single action when they visit, we may still want to simulate the performance of a single action under 2 generic conditions
- this is new functionality and we want to ensure that it is fast enough
- as part of performance regression testing – we want to ensure that the new release is no worse than the past releases
The question now is, what isolated user actions should we test? Here are some examples:
- Login / Home Page / Landing Page: the 1st page that is loaded when a user arrives on the site. It is important for it to be fast, since it is the “first impression” of the site for the user – and – it usually requires a lot of work server-side, since, by definition, we have no (or little – in the case of a returning user) cached data, so a lot of data needs to be computed or refreshed
- All pages related to checkout and payment: don’t want to lose a purchase because the site is too slow
- Pages which Analytics in Production identify as slow
- New Pages / heavily re-factored pages that are content- and/or compute-heavy
Testing the Performance of a Typical Visit
A “typical visit” can be constructed either “synthetically”, or “by replay”.
A synthetic visit is one that we build based on the nature of the site and statistics gleaned from the Production system – such as the average number of pages visited. A typical visit for a retail site would entail: login – select a category – then a sub-category – browse a couple pages – select an item – checkout and pay.
A “replay” visit is based on tracking the actual navigation of a random user on the site (e.g. using log files).
It is important to note that I should be using the plural – we need to identify multiple “typical visits”. For example, in the example above, a second typical visit would involve a couple of searches rather than browsing by category/sub-categoy.
We can also breakdown our visits to focus on specific sections or functionality of the site: search, browsing, check-out – this makes it easier to interpret the results
Let’s Not Forget Background Load!
In order for our performance test to be realistic and representative of Production, we need to simulate all the types of traffic taking place on the site – qualitatively and quantitatively – during our experiment – because each type of traffic consumes shared resources differently – whether it’s cache, database resources, access to disk, etc.
What I call “background load”, is a simulation of the typical traffic on our site. The best way to simulate it is to record it and replay it – either using a proxy server, log files, or other tools – e.g. Improving testing by using real traffic from production
One exception: If we want to characterize the performance of a specific code path – and/or benchmark it against previous versions – then we should not run any background load
How Long Should We Run the Test?
When thinking about the timing of a performance test, we first need to address the “ramp-up” or “warm-up” phase. When we launch our performance test, our system also starts “cold”: typically it has an empty cache, a small number of threads running, a few database connections set up, etc – so to obtain a realistic measurement of performance we need to wait for the system to reach its steady-state. It’s not always straightforward to tell when the system reaches steady-state, but we can get clues from monitoring critical system parameters: CPU, RAM, I/O on key servers (e.g database). Also, response time should stabilize.
Secondly, because the simulated visitors access the system in a random fashion, we need to take our measurements over an extended period of time, so as to smooth out the randomness. An easy way to figure out the exact duration is to experiment: if the results we get after 10 minutes are the same – over 10 experiments – as those that we get over 1 hour – then 10 minutes is enough.
How Many Tests Do We Run?
Depending on the test, and the environment, we may have to run it multiple times. For example, if we are running on AWS, even if we are running on reserved instances, the performance may vary between runs, depending on network traffic, load from other tenants of the physical servers, etc.
Interpreting the Results
We can look at the results in at least 2 different ways:
1/ In absolute: does the response time meet our target?
2/ Relatively to prior releases: is our response time no worse in this release than in prior releases
Performance Hygiene
Ideally, performance tests are automated and run regularly – at least after each Sprint. This allows us to catch performance regressions early.
Conversely, running performance tests after “code complete” is almost a waste of time, since this leaves us no time to remedy any serious performance issue, and thus puts us in a quandary: release a slow product on time vs release a good product late?
Common Mistake: Initial Conditions
Finally, we need to address a very common mistake, namely ignoring initial conditions.
To ground the discussion, let me give an example: we can all agree that the query “select * from TableA” will execute much faster if TableA has 1 row vs if TableA has 100M rows.
The same applies to performance testing. Just as we let the system reach steady-state before we start measuring performance, we also need to ensure that all assets impacting performance are fully loaded.
To be more specific, let’s say today is March 15, and I am working on the release that will be in Production for Black Friday in November. In order to have a meaningful performance test, I need to make sure I load my E-commerce database not just with the same number of customers that we have today (March 15), but with the projected number of customers we’ll have by the end of November! Similarly, with the number of products in the catalog, documents in the search database, etc.
This is a complex – but absolutely critical – step. Otherwise, our tests will tell us about the past, not the future.
The final consideration is to ensure that the initial conditions – as well as the test – are 100% reproducible. This means that the “initial conditions” need to be exactly reproducible: e.g. by restoring from a previously archived database, by using the same pseudo-random sequence to trigger visits, the same logs to replay background traffic, etc. Otherwise, we are simply running a different test each time. As a consequence, any benchmarking would be meaningless.
Summary
Performance testing is complex, and requires a lot of thought, careful planning and detailed work to produce results that are meaningful. Specifically, we need to:
- Model one or more individual visit profiles constructed from traffic patterns on our site / in our service
- Model visit rate based on our site’s Analytics and interpolate it to projected level during the lifetime of the release
- Generate pseudo-random sequences to model users’ arrival on the site
- Generate a model of background load and/or a mixture of individual visits that together are a good approximation of actual traffic
- Make sure to give the site/service time to warm-up (i.e. reach steady state) before starting measurements, and run the test long enough to smooth out the pseudo-random patterns. Also run multiple tests if environmental conditions cannot be fully controlled
- Finally, make sure to properly initialize the whole system – in a reproducible fashion – so as to account for all the data already present in the system.
- Finally finally, ensure that all tests conditions are reproducible, and tests are automated so that they can be run regularly – preferably upon the completion of each sprint. This ensures that performance bugs are caught early, rather than 2 weeks before the target release date.